
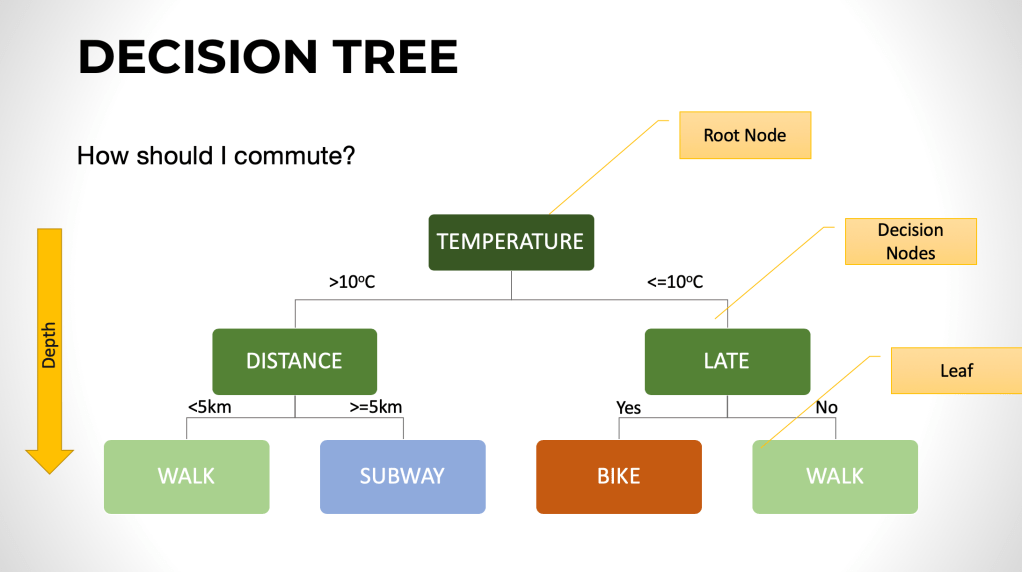
Firstly, let’s explore a basic concept, a decision tree.
Tree based learning algorithms are considered to be one of the best and mostly used supervised learning methods.
A decision tree is a flowchart-like structure in which each internal node represents a “test” on an attribute (e.g. whether a coin flip comes up heads or tails), each branch represents the outcome of the test, and each leaf node represents a class label (decision taken after computing all attributes). The paths from root to leaf represent classification rules.
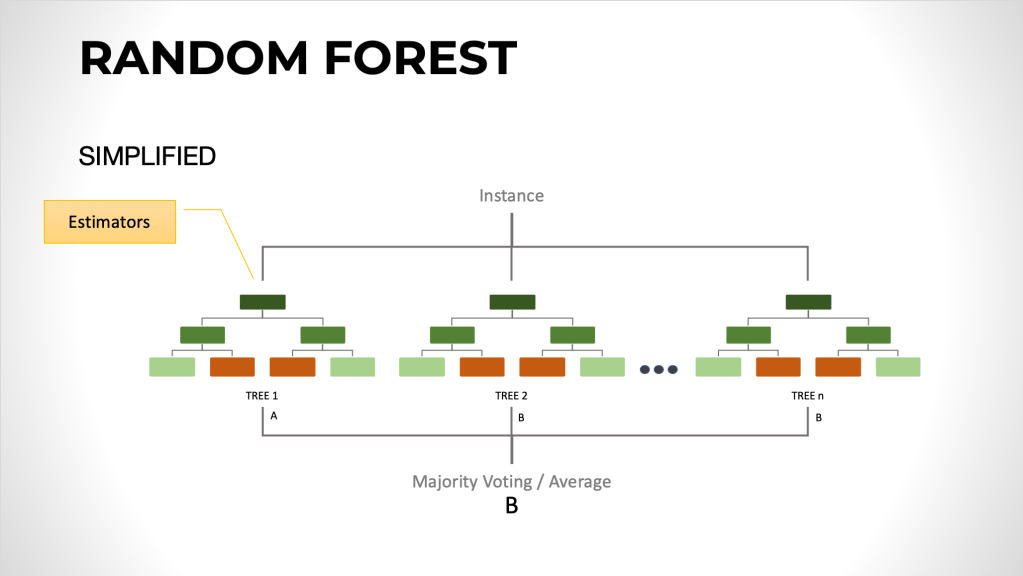
Technique that creates multiple models and then combines them to produce better results than any of the single models individually.
Boosting is an ensemble technique in which the predictors are not made independently, but sequentially.
A good example is Random Forest algorithm that uses a method called bagging.
Bagging is a simple ensemble technique in which we build many independent predictors/models/learners and combine them using some model averaging techniques. (e.g. weighted average, majority vote or normal average)
Because all the trees in a random forest are built without any consideration for any of the other trees, this is incredibly easy to parallelize, which means that it can train really quickly. So if you have 100 trees, you could train them all at the same time.
Ensemble learning method that takes an iterative approach to combining weak learners to create a strong learner by focusing on mistakes of prior iterations.
“Alone we can do so little and together we can do much”
Helen Keller
A powerful Ensemble based supervised learning algorithm able to solve classification and regression problems.
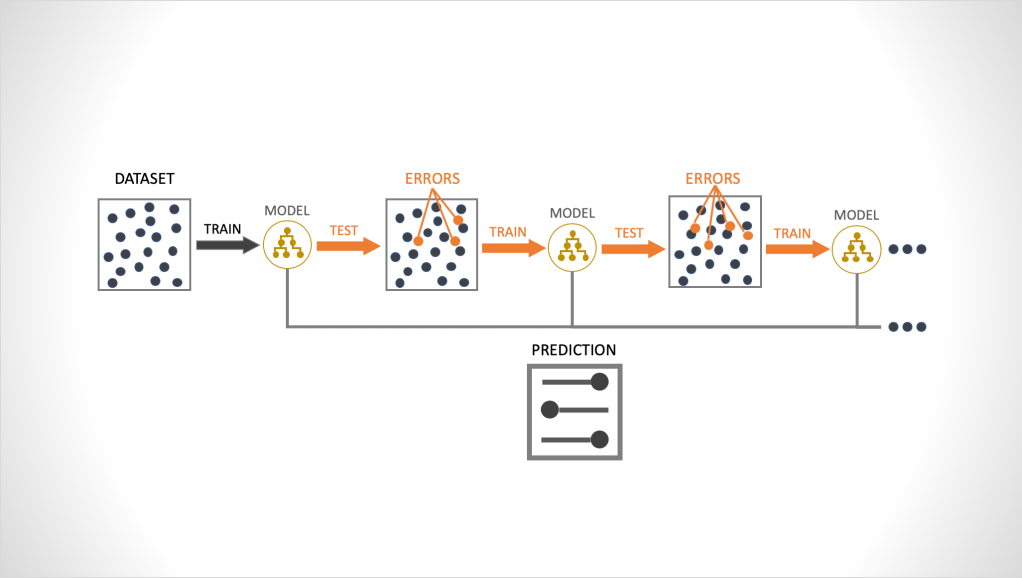
•Gradient boosting builds an ensemble of trees one-by-one, then the predictions of the individual trees are summed
•The next decision relies on the results of the tree before it in order to apply a higher weight to the ones that the previous tree got incorrect.
•The next decision tree tries to cover the discrepancy between the target function and the current ensemble prediction by reconstructing the residual.
•The next tree in the ensemble should complement well the existing trees and minimize the training error of the ensemble.
•To get a bit closer to the destination, we train a tree to reconstruct the difference between the target function and the current predictions of an ensemble, which is called the residual
•Whereas gradient boosting is iterative in that it relies on the results of the tree before it in order to apply a higher weight to the ones that the previous tree got incorrect. So boosting can’t be parallelized and so it takes much longer to train. As you get into massive training sets, this becomes a serious consideration. Another difference is that the final predictions for random forest are typically an unweighted average or an unweighted voting, while boosting uses a weighted voting.
-Gradient boosting uses decision trees as well, but they’re incredibly basic, like a decision stump.
-And then it evaluates what it gets right and what it gets wrong on that first tree, and then with the next iteration it places a heavier weight on those observations that it got wrong and it does this over and over and over again focusing on the examples it doesn’t quite understand yet until it has minimized the error as much as possible. Important fact, besides a sequential training, the prediction runs in parallel. (Extremely fast prediction response)
When to use it.
• Categorical or Continuous target variable
• Useful on nearly any type of problem
• Interested in significance of predictors
•Prediction time is important
When Not to use it.
• Transparency is important
• Training time is important or compute power is limited
• Data is really noisy
